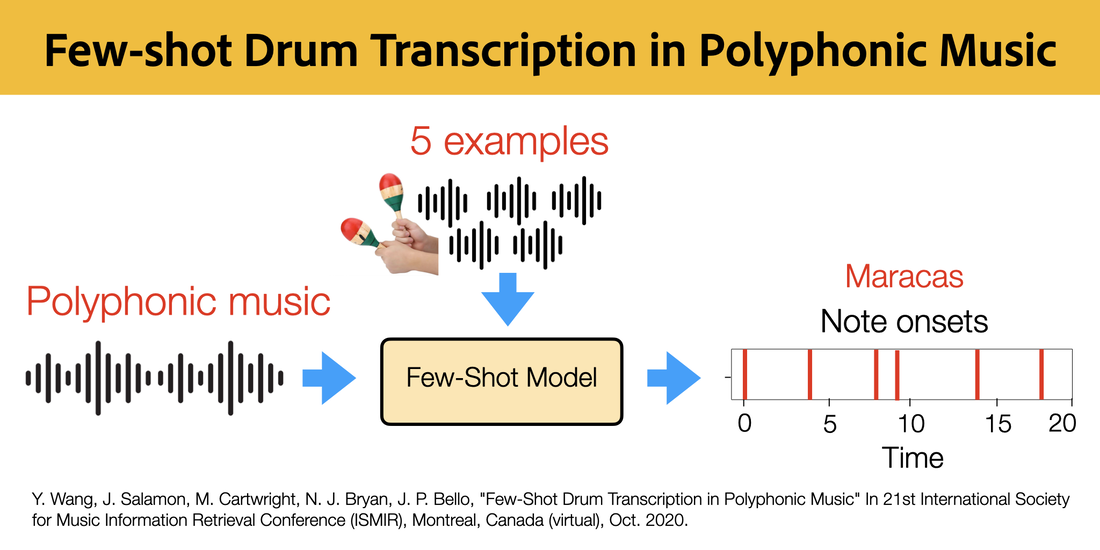
Data-driven approaches to automatic drum transcription (ADT) are often limited to a predefined, small vocabulary of percussion instrument classes. Such models cannot recognize out-of-vocabulary classes nor are they able to adapt to finer-grained vocabularies. In this work, we address open vocabulary ADT by introducing few-shot learning to the task. We train a Prototypical Network on a synthetic dataset and evaluate the model on multiple real-world ADT datasets with polyphonic accompaniment. We show that, given just a handful of selected examples at inference time, we can match and in some cases outperform a state-of-the art supervised ADT approach under a fixed vocabulary setting. At the same time, we show that our model can successfully generalize to finer-grained or extended vocabularies unseen during training, a scenario where supervised approaches cannot operate at all. We provide a detailed analysis of our experimental results, including a breakdown of performance by sound class and by polyphony.
To learn more please read out paper:
Few-Shot Drum Transcription in Polyphonic Music
Y. Wang, J. Salamon, M. Cartwright, N. J. Bryan, J. P. Bello
In 21st International Society for Music Information Retrieval Conference (ISMIR), Montreal, Canada (virtual), Oct. 2020.
You can find more related materials including a short video presentation and a poster here:
https://program.ismir2020.net/poster_1-14.html
To learn more please read out paper:
Few-Shot Drum Transcription in Polyphonic Music
Y. Wang, J. Salamon, M. Cartwright, N. J. Bryan, J. P. Bello
In 21st International Society for Music Information Retrieval Conference (ISMIR), Montreal, Canada (virtual), Oct. 2020.
You can find more related materials including a short video presentation and a poster here:
https://program.ismir2020.net/poster_1-14.html



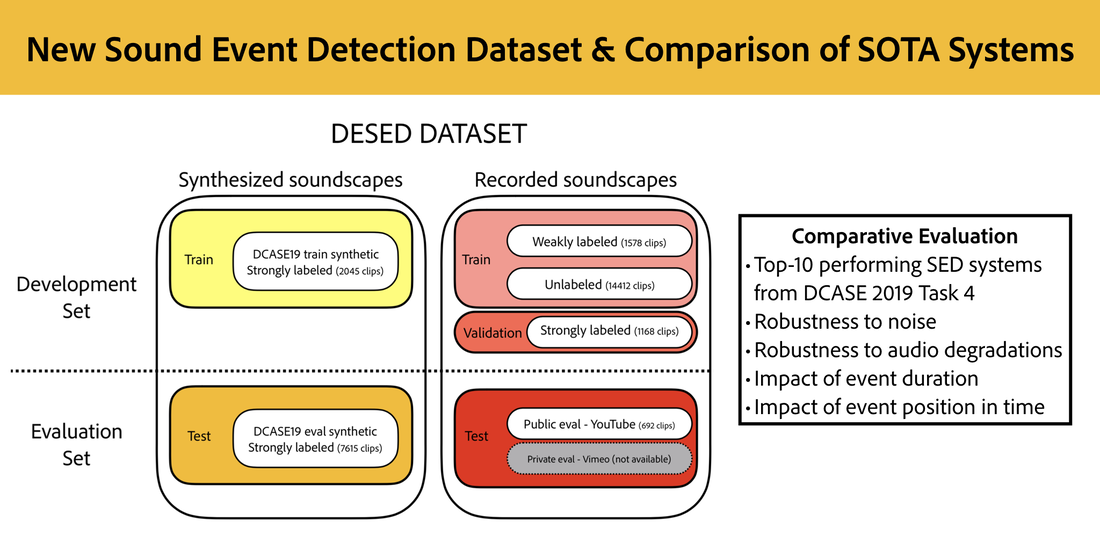
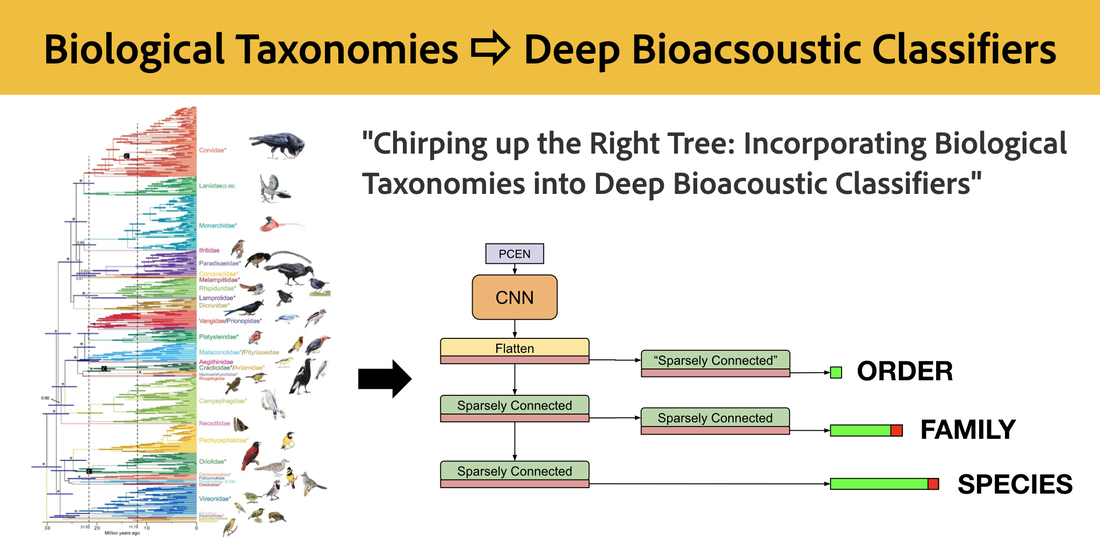

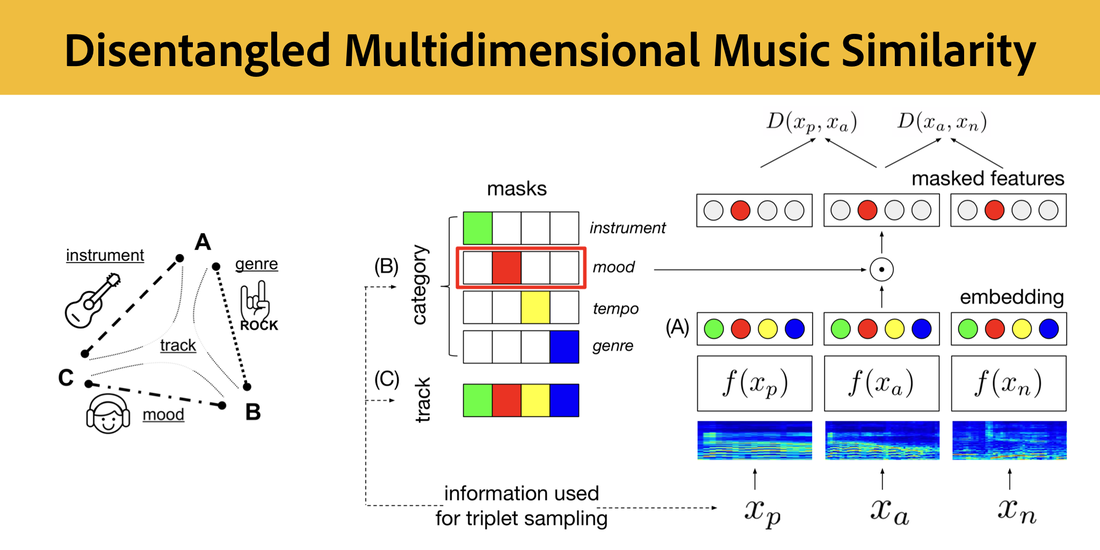
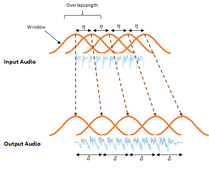


 RSS Feed
RSS Feed
