
I'm happy to report I've been elected to the IEEE Audio and Acoustic Signal Processing Technical Committee.
The AASP TC's mission is to support, nourish and lead scientific and technological development in all areas of audio and acoustic signal processing. These areas are currently seeing increased levels of interest and significant growth providing a fertile ground for a broad range of specific and interdisciplinary research and development. Ranging from array processing for microphones and loudspeakers to music genre classification, from psychoacoustics to machine learning, from consumer electronics devices to blue-sky research, this remit encompasses countless technical challenges and many hot topics. The TC numbers some 30 appointed volunteer members drawn roughly equally from leading academic and industrial organizations around the world, unified by the common aim to offer their expertise in the service of the scientific community.
Looking forward to doing my bit for this excellent scientific community!
The AASP TC's mission is to support, nourish and lead scientific and technological development in all areas of audio and acoustic signal processing. These areas are currently seeing increased levels of interest and significant growth providing a fertile ground for a broad range of specific and interdisciplinary research and development. Ranging from array processing for microphones and loudspeakers to music genre classification, from psychoacoustics to machine learning, from consumer electronics devices to blue-sky research, this remit encompasses countless technical challenges and many hot topics. The TC numbers some 30 appointed volunteer members drawn roughly equally from leading academic and industrial organizations around the world, unified by the common aim to offer their expertise in the service of the scientific community.
Looking forward to doing my bit for this excellent scientific community!

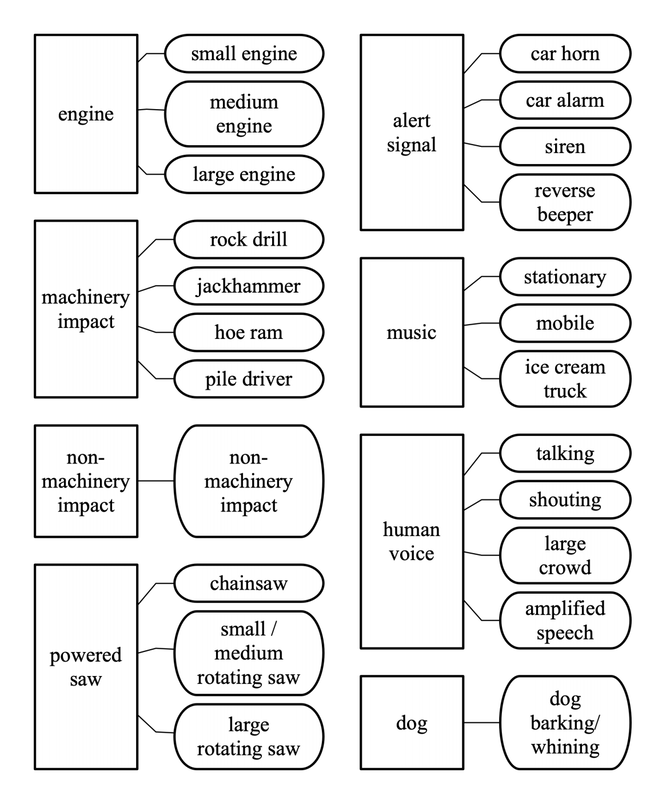
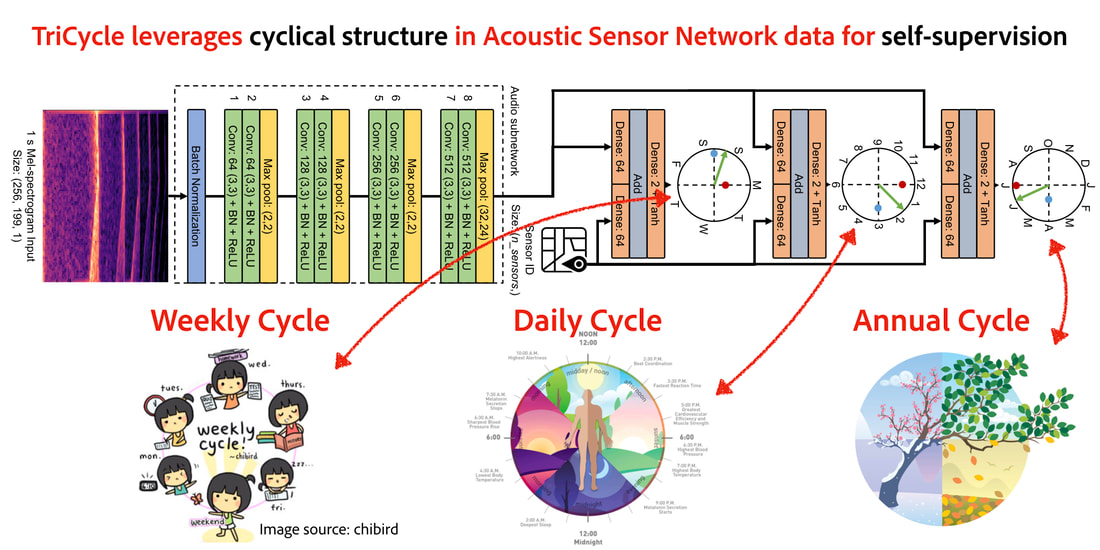
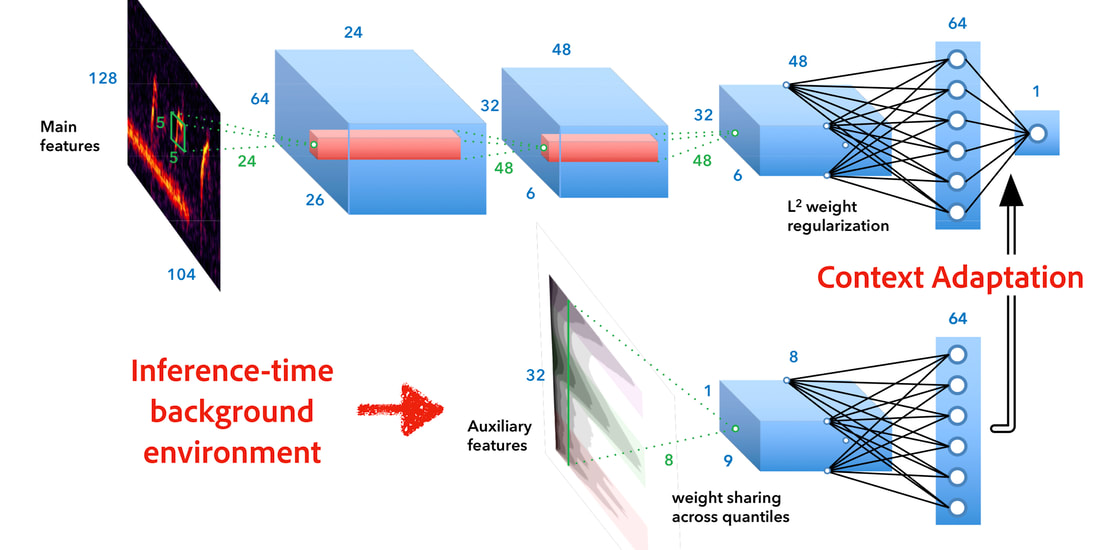
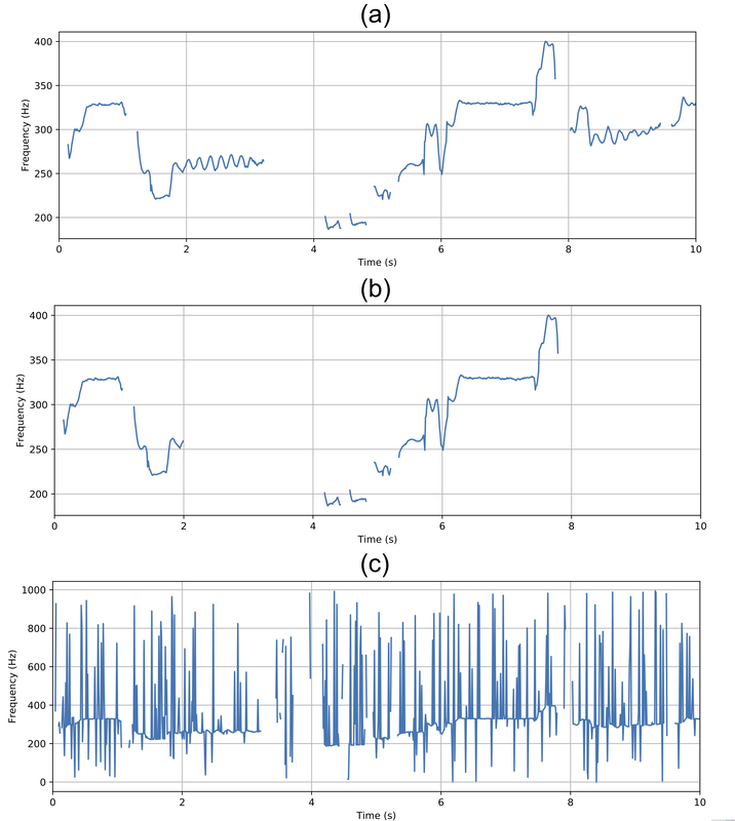

 RSS Feed
RSS Feed
