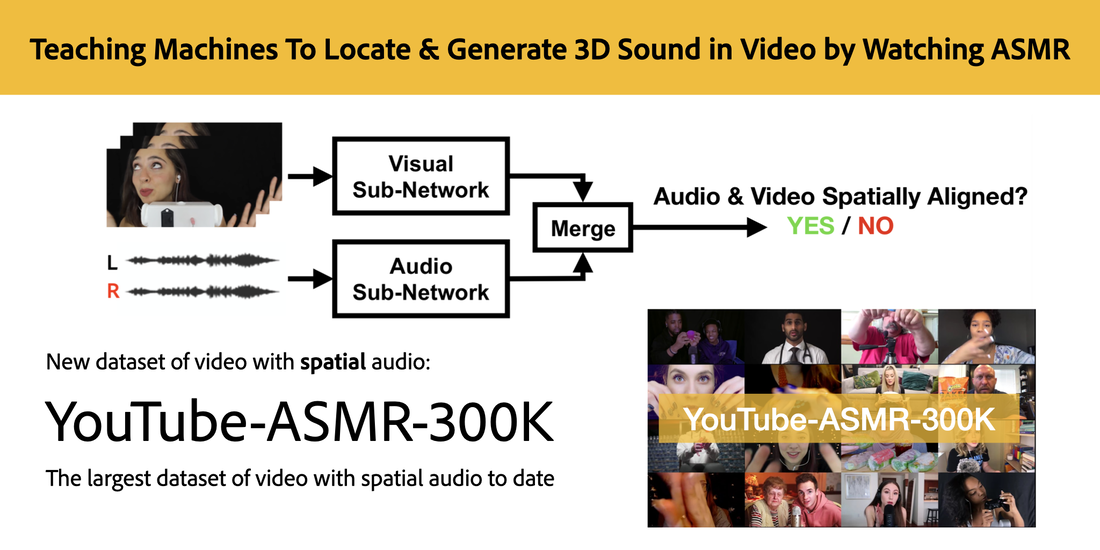
We're excited to release the YouTube-ASMR-300K dataset, the largest video dataset with spatial audio published to date!

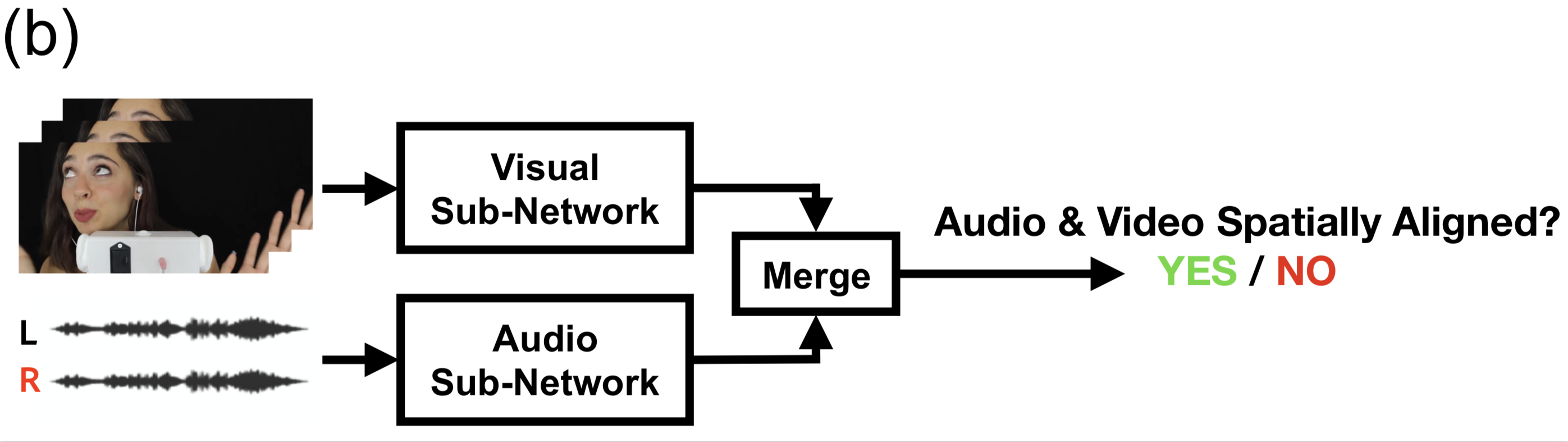
Learning from videos with spatial audio is a relatively new domain. While the amount of spatial audio content is increasing, currently there are few video datasets with spatial audio in which the visual content is spatially aligned with the audio content. We therefore introduce a new large-scale dataset of ASMR videos collected from YouTube that contains stereo audio.
ASMR (autonomous sensory meridian response) videos are readily available online and typically feature an individual actor or "ASMRtist" making different sounds while facing towards a camera set up with
stereo/binaural or paired microphones.
The audio in these videos contains binaural cues that, when listened to with headphones, create a highly immersive experience in which listeners perceive the sounds as if they were happening around
them. Thus there is strong correspondence between the visual and spatial audio content in these videos.
​Our full dataset, YouTube-ASMR-300K, consists of approximately 300K 10-second video clips with spatial audio. From this full dataset, we also manually curated a subset of 30K clips from 30 ASMR channels that feature more sound events moving spatially for training our models. We call this curated dataset YouTube-ASMR. We split the video clips into training, validation, and test sets in an 80-10-10 ratio.
Compared to the existing datasets, YouTube-ASMR300K is (1) larger by at least 8X, (2) collected
in-the-wild, and (3) contains sound sources in motion (e.g., a user waves a tuning fork across the field of view), which is important for training models on diverse spatial cues. how YouTube-ASMR and YouTube-ASMR-300K compare to existing video dataset with spatial audio:
|
Dataset
|
​# Unique videos
|
Durations (hours)
|
|
Lu et al., ICIP 2019
|
​N/R
|
9.3
|
|
FAIR-play
|
N/R (2000 10-sec clips in total)
|
5.2
|
|
YouTube-360
|
1146
|
114
|
|
YouTube-ASMR
|
3520
|
96
|
|
YouTube-ASMR-300K
|
33725
|
904
|
​YouTube-ASMR-300K was compiled as part of our CVPR 2020 paper:
Telling Left From Right: Learning Spatial Correspondence of Sight and Sound
K. Yang, B. Russell, J. Salamon
The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 9932-9941.
[CVF][PDF][BibTeX]
The YouTube-ASMR-300K dataset and other project materials are available on our companion website:
https://karreny.github.io/telling-left-from-right/
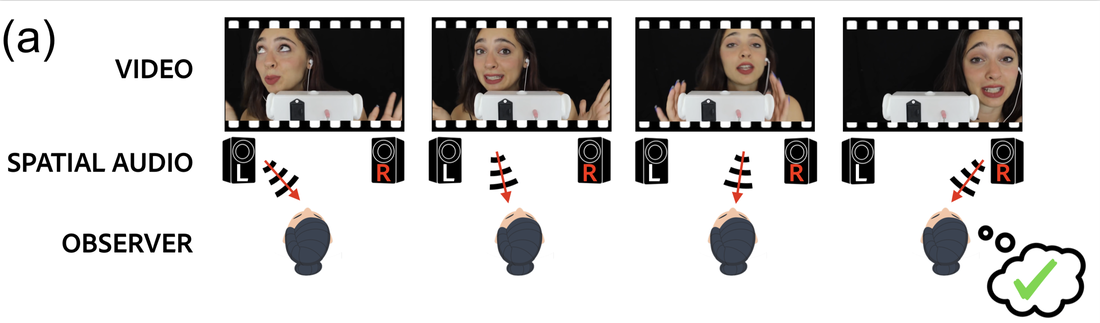


 RSS Feed
RSS Feed
