The Neumerator will take any audio file and generate a medieval neume-style manuscript from it!

As you might have guessed this is a hack... more the specifically the hack I worked on together with Kristin Olson and Tejaswinee Kelkar during this month's Monthly Music Hackathon NYC (where I also gave a talk about melody extraction).
How does The Neumerator work?
You start by choosing a music recording, for example "Ave Generosa" by Hildegard Von Bingen (to keep things simple we'll work just with the first 20 seconds or so):
The first step is to extract the pitch sequence of the melody, for which we use Melodia, the melody extraction algorithm I developed as part of my PhD. The result looks like this (pitch vs time):
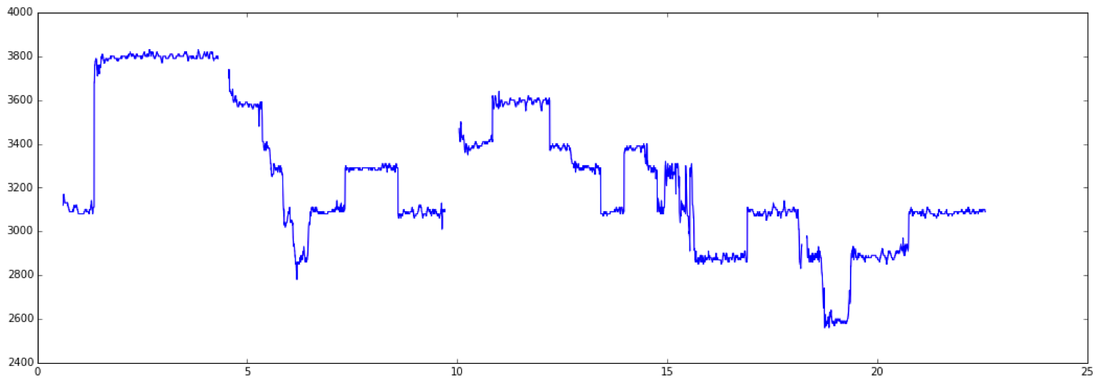
Once we have the continuos pitch sequence, we need to discretize it into notes. Whilst we could load the sequence into a tool such as Tony to perform clever note segmentation, for our hack we wanted to keep things simple (and fully automated), so we implemented our own very simple note segmentation process. First, we quantize the pitch curve into semitones:
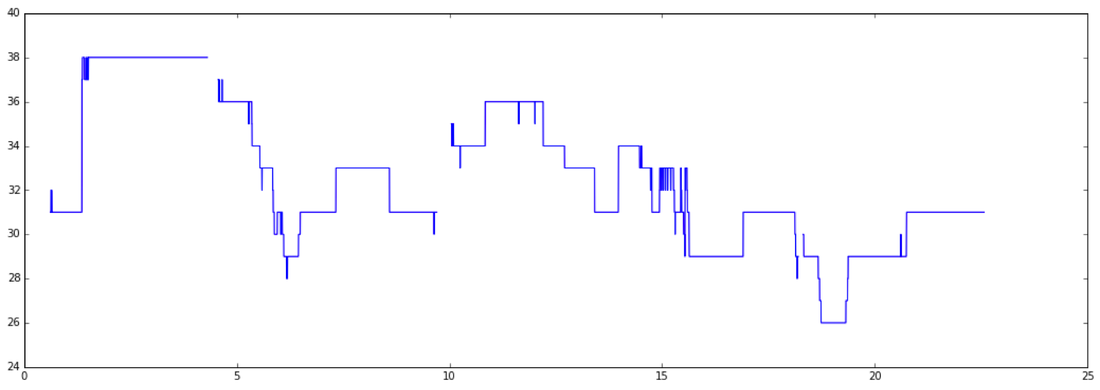
Then we smooth out very short glitches using a majority-vote sliding window:
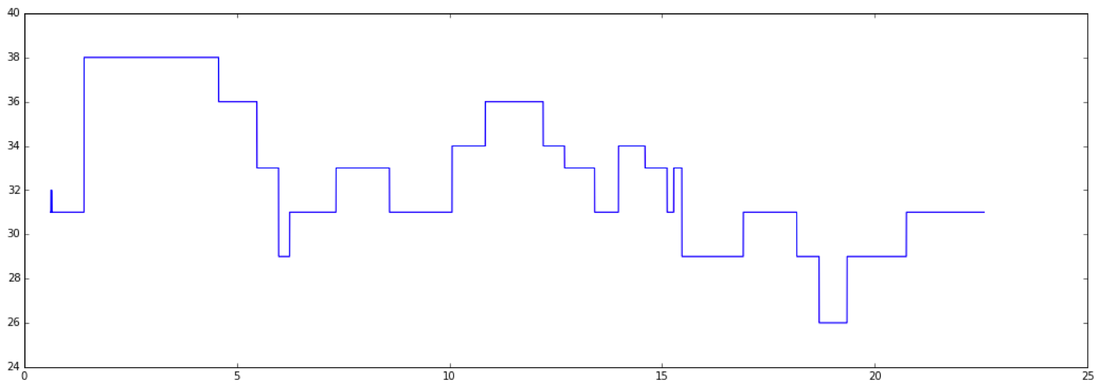
Then we can keep just the points where the pitch changes, and we're starting to get close to something that looks kinda of "neumey":
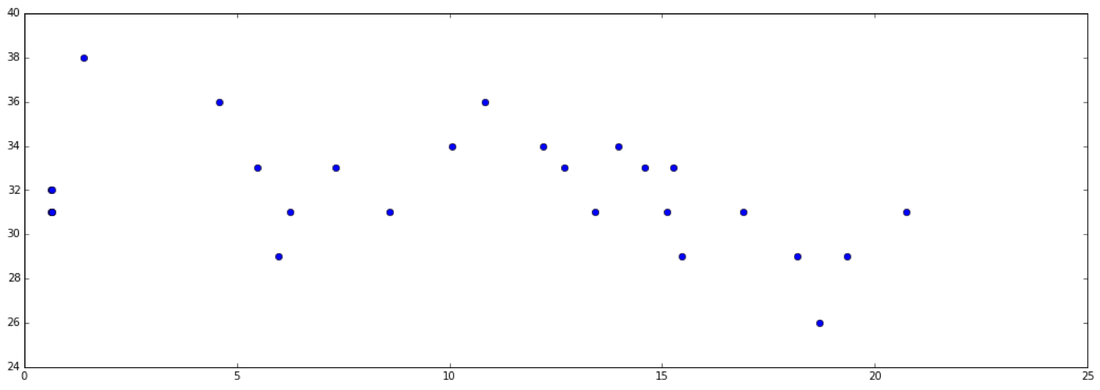
Finally, we run it through the neumerator manuscript generator which applies our secret combination of magic, unicorns and gregorian chant, and voila!

Being a hack and all, The Neumerator does have its limitations - currently we can only draw points (rather than connecting them into actual neumes), everything goes on a single four-line staff (regardless of the duration of the audio being processed), and of course the note quantization step is pretty basic. Oh, and the mapping of the estimated notes onto the actual pixel positions of the manuscript is a total hack. But hey, that's what future hackathons are for!
Want to take The Neumerator to the next level? It's all on GitHub:
github.com/justinsalamon/neumerator
Want to take The Neumerator to the next level? It's all on GitHub:
github.com/justinsalamon/neumerator





 RSS Feed
RSS Feed
