In the context of automatic speech recognition and acoustic event detection, an adaptive procedure named per-channel energy normalization (PCEN) has recently shown to outperform the pointwise logarithm of mel-frequency spectrogram (logmelspec) as an acoustic frontend. This article investigates the adequacy of PCEN for spectrogram-based pattern recognition in far-field noisy recordings, both from theoretical and practical standpoints. First, we apply PCEN on various datasets of natural acoustic environments and find empirically that it Gaussianizes distributions of magnitudes while decorrelating frequency bands. Secondly, we describe the asymptotic regimes of each component in PCEN: temporal integration, gain control, and dynamic range compression. Thirdly, we give practical advice for adapting PCEN parameters to the temporal properties of the noise to be mitigated, the signal to be enhanced, and the choice of time-frequency representation. As it converts a large class of real-world soundscapes into additive white Gaussian noise (AWGN), PCEN is a computationally efficient frontend for robust detection and classification of acoustic events in heterogeneous environments.
Read the full paper here:
Per-Channel Energy Normalization: Why and how
V. Lostanlen, J. Salamon, M. Cartwright, B. McFee, A. Farnsworth, S. Kelling, and J. P. Bello.
IEEE Signal Processing Letters, 26(1): 39–43, Jan. 2019.
​[IEEE][PDF][BibTeX][Copyright]
Here's a plot from our paper comparing the application of log vs PCEN on a mel-spectrogram computed from an audio recording captured by a remote acoustic sensor for avian flight call detection (as part of our BirdVox project). In the top plot (log) we clearly see energy from undesired noise sources such as insects and a car, whereas in the bottom plot (PCEN) we see these confounding factors have been attenuated, while the flight calls we wish to detect (which appear as very short chirps) are kept.
Read the full paper here:
Per-Channel Energy Normalization: Why and how
V. Lostanlen, J. Salamon, M. Cartwright, B. McFee, A. Farnsworth, S. Kelling, and J. P. Bello.
IEEE Signal Processing Letters, 26(1): 39–43, Jan. 2019.
​[IEEE][PDF][BibTeX][Copyright]
Here's a plot from our paper comparing the application of log vs PCEN on a mel-spectrogram computed from an audio recording captured by a remote acoustic sensor for avian flight call detection (as part of our BirdVox project). In the top plot (log) we clearly see energy from undesired noise sources such as insects and a car, whereas in the bottom plot (PCEN) we see these confounding factors have been attenuated, while the flight calls we wish to detect (which appear as very short chirps) are kept.
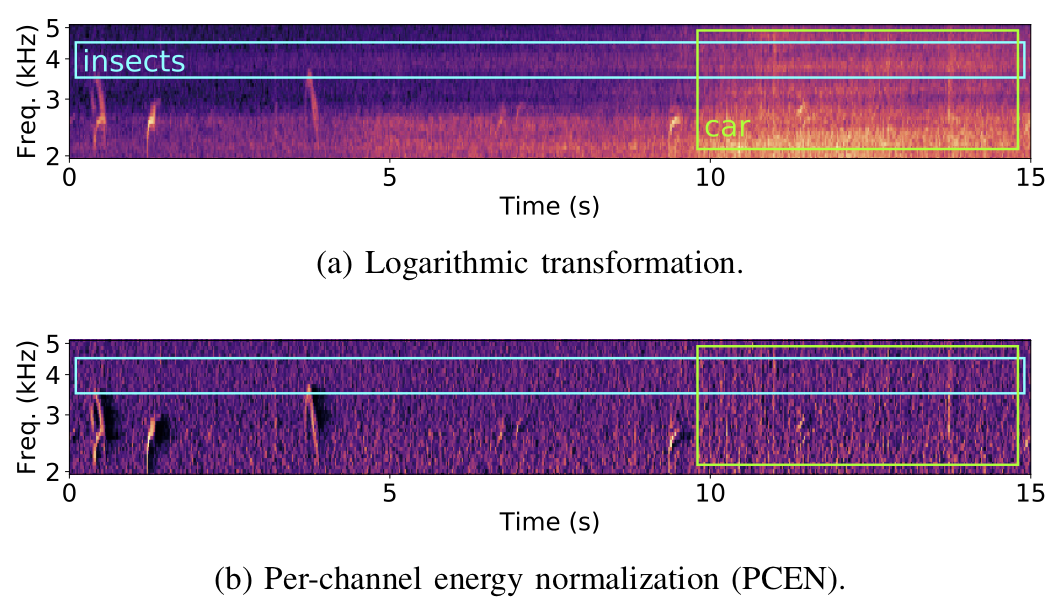
Fig. 1. A soundscape comprising bird calls, insect stridulations, and a passing vehicle. The logarithmic transformation of the mel-frequency spectrogram (a) maps all magnitudes to a decibel-like scale, whereas per-channel energy normalization (b) enhances transient events (bird calls) while discarding stationary noise (insects) as well as slow changes in loudness (vehicle). Data provided by BirdVox. Mel-frequency spectrogram and PCEN computed with default librosa 0.6.1 parameters and T = 60 ms (see Section IV).


 RSS Feed
RSS Feed
