Melody Extraction
Melody extraction is the task of automatically estimating the fundamental frequency corresponding to the pitch of the predominant melodic line of a piece of polyphonic (or homophonic) music. Other names for this task include Audio Melody Extraction, Predominant Melody Extraction, Predominant Melody Estimation and Predominant Fundamental Frequency (F0) Estimation.
Melody extraction is not source separation, i.e. melody extraction won't separate the lead voice from a recording (though it may help you to do this at a later step!).
Melody extraction is:
(1) estimating when the melody is present and when it is not (also referred to as voicing detection).
(2) estimating the correct pitch of the melody when it is present.
OK, but why would anyone want to do this? If you're in a hurry, you can jump to the Applications section of this page to see what kind of things we can do with melody extraction.
How is it done? In the following section you'll find a short and non-scientist friendly explanation of how our algorithm performs melody extraction. In the MIREX 2011 evaluation campaign, our approach obtained the highest mean overall accuracy. This doesn't mean it's perfect - it's not. But in some cases it can work quite well.
Looking for a more rigorous explanation?
You can find it in this paper (also available on my Publications page with additional links to IEEE, DOI and a BibTex file):
Looking for a general review of melody extraction algorithms?
You can find it in this paper:
Looking for a whole book on melody extraction and its applications?
Can I hear a demo?
Sure - head down to the Demo section of this page to hear some music excerpts and their corresponding melody pitch as extracted by our algorithm.
Can I use your algorithm?
Yes! Head down to the Software section where you can find more details on how to use our algorithm. Please remember to cite our IEEE TASLP paper in any publication in which the plugin was used - thanks!
Where can I get more information?
My Publications page might be a good place to start :)
Melody extraction is not source separation, i.e. melody extraction won't separate the lead voice from a recording (though it may help you to do this at a later step!).
Melody extraction is:
(1) estimating when the melody is present and when it is not (also referred to as voicing detection).
(2) estimating the correct pitch of the melody when it is present.
OK, but why would anyone want to do this? If you're in a hurry, you can jump to the Applications section of this page to see what kind of things we can do with melody extraction.
How is it done? In the following section you'll find a short and non-scientist friendly explanation of how our algorithm performs melody extraction. In the MIREX 2011 evaluation campaign, our approach obtained the highest mean overall accuracy. This doesn't mean it's perfect - it's not. But in some cases it can work quite well.
Looking for a more rigorous explanation?
You can find it in this paper (also available on my Publications page with additional links to IEEE, DOI and a BibTex file):
- J. Salamon and E. Gómez, "Melody Extraction from Polyphonic Music Signals using Pitch Contour Characteristics", IEEE Transactions on Audio, Speech and Language Processing, 20(6):1759-1770, Aug. 2012.
Looking for a general review of melody extraction algorithms?
You can find it in this paper:
- J. Salamon, E. Gómez, D. P. W. Ellis and G. Richard, "Melody Extraction from Polyphonic Music Signals: Approaches, Applications and Challenges", IEEE Signal Processing Magazine, 31(2):118-134, Mar. 2014.
Looking for a whole book on melody extraction and its applications?
- Check out my PhD Thesis!
Can I hear a demo?
Sure - head down to the Demo section of this page to hear some music excerpts and their corresponding melody pitch as extracted by our algorithm.
Can I use your algorithm?
Yes! Head down to the Software section where you can find more details on how to use our algorithm. Please remember to cite our IEEE TASLP paper in any publication in which the plugin was used - thanks!
Where can I get more information?
My Publications page might be a good place to start :)
How Is It Done?
There are, in fact, many ways to go about it. What I describe below is our way of doing it (see aforementioned paper). Our approach is comprised of four blocks: Sinusoid Extraction, Salience Function, Contour Creation and Melody Selection:
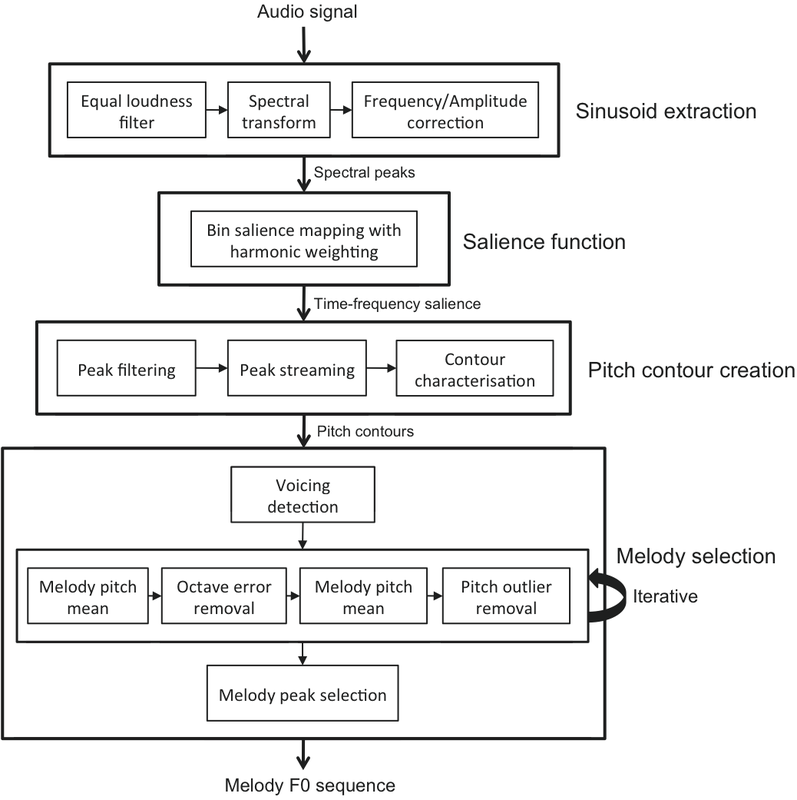
Sinusoid Extraction
In this block our goal is to find out which frequencies are present in the audio signal at every point in time. We will later use these to deduce which pitches are present in the signal at every point in time. But before we do this, we apply an Equal Loudness filter to the audio signal. This filter enhances frequencies we are perceptually more sensitive to, and attenuates those to which we are less sensitive. Apart from making "perceptual sense", it turns out this filter enhances the frequency range in which the melody is often found, and attenuates the low-frequency range where we are less likely to find the melody.
In this block our goal is to find out which frequencies are present in the audio signal at every point in time. We will later use these to deduce which pitches are present in the signal at every point in time. But before we do this, we apply an Equal Loudness filter to the audio signal. This filter enhances frequencies we are perceptually more sensitive to, and attenuates those to which we are less sensitive. Apart from making "perceptual sense", it turns out this filter enhances the frequency range in which the melody is often found, and attenuates the low-frequency range where we are less likely to find the melody.
Next, we chop the signal into small blocks for further processing, each block representing a specific moment in time. We apply the Discrete Fourier Transform (DFT) to each block, which is a transform that gives us the "intensity" of each frequency in the audio block. The spectral peaks (sinusoids) are the peaks of this transform, i.e. they are the "most energetic" frequencies present in the audio signal at this moment in time (i.e. in this block). So, for each block we keep only these peak frequencies, and discard all other frequencies. However, the DFT has a limited frequency resolution, meaning the value (in Hertz) of these "energetic" frequencies might be a little off. To cope with this we refine the frequency estimate given to us by the DFT by computing the instantaneous frequency (IF) of each spectral peak using the difference between consecutive phase spectra. Now, for each moment in time (represented by one audio block) we have a set of (accurate) "energetic" frequencies that are present in the signal:
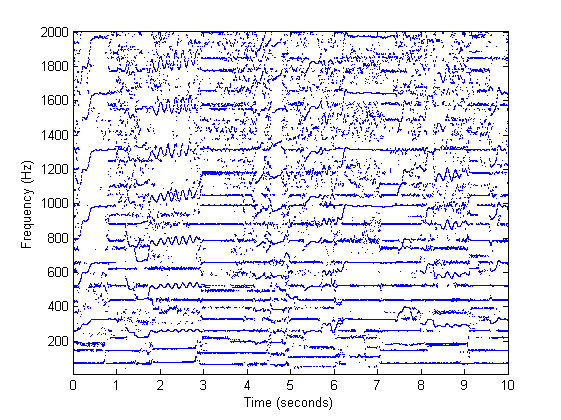
Salience Function
Now that we know which frequencies are present in the audio signal in each moment in time, we use them to estimate which pitches are present in each moment in time and how salient they are. Remember that whilst frequency and pitch are related, they are not the same thing! To obtain an estimate of how salient each pitch is, we use harmonic summation - i.e. for every possible pitch (within a reasonable range) we search for a harmonic series of frequencies that would contribute to our perception of this pitch. The (weighted) sum of the energy of these harmonic frequencies is considered the "salience" of this pitch. We repeat this for every moment in time (every block), leading to a representation of pitch salience over time, which we refer to as a salience function:
Now that we know which frequencies are present in the audio signal in each moment in time, we use them to estimate which pitches are present in each moment in time and how salient they are. Remember that whilst frequency and pitch are related, they are not the same thing! To obtain an estimate of how salient each pitch is, we use harmonic summation - i.e. for every possible pitch (within a reasonable range) we search for a harmonic series of frequencies that would contribute to our perception of this pitch. The (weighted) sum of the energy of these harmonic frequencies is considered the "salience" of this pitch. We repeat this for every moment in time (every block), leading to a representation of pitch salience over time, which we refer to as a salience function:

Contour Creation
From the salience function, we track pitch contours. A pitch contour represents a series of consecutive pitch values which are continuous in both time and frequency. The duration of a pitch contour can be anything from a single note to a short phrase. To track these contours, we take the peaks of the salience function at each moment in time, since they represent the most salient pitches. We then use a set of cues based on auditory streaming to group these peaks into contours:
From the salience function, we track pitch contours. A pitch contour represents a series of consecutive pitch values which are continuous in both time and frequency. The duration of a pitch contour can be anything from a single note to a short phrase. To track these contours, we take the peaks of the salience function at each moment in time, since they represent the most salient pitches. We then use a set of cues based on auditory streaming to group these peaks into contours:
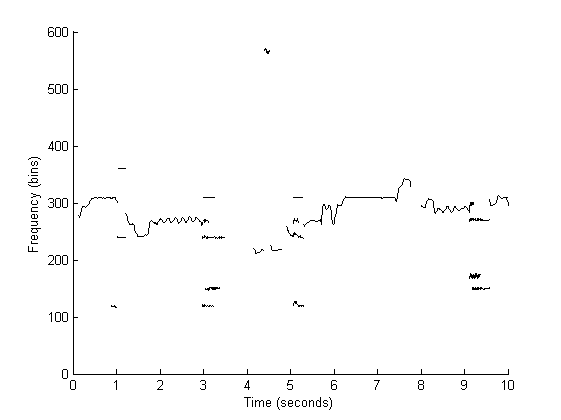
Melody Selection
So, now that we have all of these pitch contours, our remaining task is to determine which ones belong to the melody and which don't. This is the tricky bit...
Our approach is based on the calculation of contour characteristics. That is, for each contour, we compute a set of characteristics based on its salience and pitch evolution. We compute characteristics such as the contour's average pitch height and its salience, the amount of deviation in the contour's pitch trajectory, and even check if the contour contains vibrato or not. By studying the distribution of these characteristics for contours that belong to melodies and contours that belong to accompaniments, we were able to devise a set of rules for filtering out non-melodic contours! After applying these filtering rules, the remaining melody looks something like this:
So, now that we have all of these pitch contours, our remaining task is to determine which ones belong to the melody and which don't. This is the tricky bit...
Our approach is based on the calculation of contour characteristics. That is, for each contour, we compute a set of characteristics based on its salience and pitch evolution. We compute characteristics such as the contour's average pitch height and its salience, the amount of deviation in the contour's pitch trajectory, and even check if the contour contains vibrato or not. By studying the distribution of these characteristics for contours that belong to melodies and contours that belong to accompaniments, we were able to devise a set of rules for filtering out non-melodic contours! After applying these filtering rules, the remaining melody looks something like this:
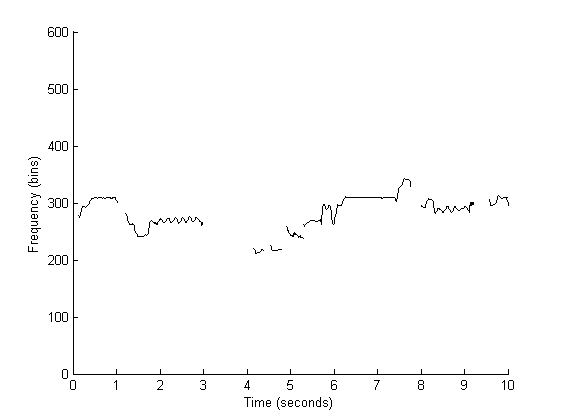
Demo
Here are some audio examples of melody pitch sequences extracted using our algorithm (requires Flash). For each example there are 3 audio files:
To hear more examples you can visit my PhD Thesis page.
Vocal Jazz:
- In the first you can listen to an excerpt of the original song.
- In the second, the pitch estimated by our algorithm.
- In the third, the original song in the left channel and the estimated pitch in the right channel (I recommend using headphones for this file).
To hear more examples you can visit my PhD Thesis page.
Vocal Jazz:
Original
Melody
Mix (left channel: original, right channel: melody)
Pop:
Original
Melody
Mix (left channel: original, right channel: melody)
Opera:
Original
Melody
Mix (left channel: original, right channel: melody)
Instrumental Jazz:
Original
Melody
Mix (left channel: original, right channel: melody)
Flamenco:
Original
Melody
Mix (left channel: original, right channel: melody)
Applications
Melody extraction is a technology that has a variety of application areas, for both the industry and research communities. Here are some examples:
Query by Humming
Ever had a tune stuck in your head whose name you just couldn't remember? Query by humming systems allow you to sing the melody of a song to your computer and it will search for it and give back information about the song. In order to find your song, the system must have a database of melodies against which it can compare the melody you've just sung. This is where melody extraction comes in - instead of manually transcribing millions of melodies, with melody extraction this process can be done automatically!
- I know a service like this - Shazam!
No, not exactly. Shazam is an audio fingerprinting service. This means it can only detect the song if you play it the original version of the song. Singing to Shazam won't work.
- Oh I see. Ah wait, how about Midomi, SoundHound or Tunebot? I can sing to those.
Yes! These are indeed Query by Humming services. However, they have one (considerable) limitation - their collection of songs (the melody database) is created by the users themselves. This means that for a song to appear in the database, at least one user must have already sung it. If no one has already sung the song you are thinking of, the system will never find it. This problem could be avoided using automatic melody extraction.
- Cool. So... are there any commercial systems out there that use automatic melody extraction?
To the best of my knowledge (2012), not yet. But here's our research paper where we describe a prototype system:
J. Salamon, J. Serrà and E. Gómez, "Tonal Representations for Music Retrieval: From Version Identification to Query-by-Humming", International Journal of Multimedia Information Retrieval, special issue on Hybrid Music Information Retrieval, In Press (accepted Nov. 2012).
[Springer][DOI][PDF][BibTex]
Interested in reading more? Please go to my Publications page.
Version Identification (detecting cover songs)
Another application is version identification. If we can extract the melodies of two songs, we can compare them and try to determine whether the two songs have the same melody. In this way, we can determine whether two recordings are versions of the same underlying piece or not. Apart from detecting copyright violations (not fun), this can help analyze how different artists influence each other, or learn which aspects of the melody are preserved between versions and which are changed. Finding different versions of a song you like is also quite simply fun! Here's our paper on version identification using the melody (yes, it's the same paper as the one above describing our prototype audio-to-audio QBH system):
J. Salamon, J. Serrà and E. Gómez, "Tonal Representations for Music Retrieval: From Version Identification to Query-by-Humming", International Journal of Multimedia Information Retrieval, special issue on Hybrid Music Information Retrieval, In Press (accepted Nov. 2012).
[Springer][DOI][PDF][BibTex]
Interested in reading more? Please go to my Publications page.
Automatic Transcription
Extraction the (continuous) pitch of the melody is the first step towards transcription into notes (a.k.a. symbolic notation). Automatic transcription has a very wide range of uses, including composition, music education and music analysis. Importantly, automatic transcription can help us create symbolic representations of pieces that belong to music traditions which, unlike Western music, don't have an established score notation! One such example is Flamenco music, and you can read more about automatic transcription of Flamenco singing here:
E. Gómez, F. Cañadas, J. Salamon, J. Bonada, P. Vera and P. Cabañas, "Predominant Fundamental Frequency Estimation vs Singing Voice Separation for the Automatic Transcription of Accompanied Flamenco Singing", in Proc. 13th International Society for Music Information Retrieval Conference (ISMIR 2012), Porto, Portugal, October 2012.
[ISMIR][BibTeX]
Interested in reading more? Please go to my Publications page.
Genre Classification
Musical genres are distinguished by their different musical characteristics. The set of characteristics used to define a genre is very large (and may vary from genre to genre and from person to person!), and can include instrumentation, rhythm, timbre, harmony, production method, and... the characteristics of the melody! Clearly, pop melodies are quite different from flamenco melodies, which are very different from soloist parts in an Opera for example! Thus, if we can extract the melody, we can compute different features to characterize it, and based on these features try to determine the musical genre of the piece from which the melody came. This could (for example) help us to automatically sort our personal music collection based on genre! You can read more about genre classification using melody characteristics here:
J. Salamon, B. Rocha and E. Gómez, "Musical Genre Classification using Melody Features Extracted from Polyphonic Music Signals", in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, March 25-30, 2012.
[ICASSP][PDF][BibTeX]
Interested in reading more? Please go to my Publications page.
Motif and Pattern Analysis
Some musical styles are characterized by the use of melodic motifs which repeat in different forms through the musical piece. Some sub-genres can even be distinguished based on the type of motifs used in their melodies. Automatic melody extraction is a necessary first step for the computational analysis of melodic motifs. In the following paper you can find information about melodic motif analysis in Flamenco music, where our algorithm was used for the melody extraction step:
A. Pikrakis, F. Gómez, S. Oramas, J. M. D. Báñez, J. Mora, F. Escobar, E. Gómez and J. Salamon, "Tracking Melodic Patterns in Flamenco Singing by Analyzing Polyphonic Music Recordings", in Proc. 13th International Society for Music Information Retrieval Conference (ISMIR 2012), Porto, Portugal, October 2012.
[ISMIR][BibTeX]
Interested in reading more? Please go to my Publications page.
Fun
Once you have the melody's pitch sequence, you can synthesize it with whichever instrument (or voice) you fancy! Check out my blog post on how to replace your favourite singer with a robot using the Vocaloid singing voice synthesizer!
Query by Humming
Ever had a tune stuck in your head whose name you just couldn't remember? Query by humming systems allow you to sing the melody of a song to your computer and it will search for it and give back information about the song. In order to find your song, the system must have a database of melodies against which it can compare the melody you've just sung. This is where melody extraction comes in - instead of manually transcribing millions of melodies, with melody extraction this process can be done automatically!
- I know a service like this - Shazam!
No, not exactly. Shazam is an audio fingerprinting service. This means it can only detect the song if you play it the original version of the song. Singing to Shazam won't work.
- Oh I see. Ah wait, how about Midomi, SoundHound or Tunebot? I can sing to those.
Yes! These are indeed Query by Humming services. However, they have one (considerable) limitation - their collection of songs (the melody database) is created by the users themselves. This means that for a song to appear in the database, at least one user must have already sung it. If no one has already sung the song you are thinking of, the system will never find it. This problem could be avoided using automatic melody extraction.
- Cool. So... are there any commercial systems out there that use automatic melody extraction?
To the best of my knowledge (2012), not yet. But here's our research paper where we describe a prototype system:
J. Salamon, J. Serrà and E. Gómez, "Tonal Representations for Music Retrieval: From Version Identification to Query-by-Humming", International Journal of Multimedia Information Retrieval, special issue on Hybrid Music Information Retrieval, In Press (accepted Nov. 2012).
[Springer][DOI][PDF][BibTex]
Interested in reading more? Please go to my Publications page.
Version Identification (detecting cover songs)
Another application is version identification. If we can extract the melodies of two songs, we can compare them and try to determine whether the two songs have the same melody. In this way, we can determine whether two recordings are versions of the same underlying piece or not. Apart from detecting copyright violations (not fun), this can help analyze how different artists influence each other, or learn which aspects of the melody are preserved between versions and which are changed. Finding different versions of a song you like is also quite simply fun! Here's our paper on version identification using the melody (yes, it's the same paper as the one above describing our prototype audio-to-audio QBH system):
J. Salamon, J. Serrà and E. Gómez, "Tonal Representations for Music Retrieval: From Version Identification to Query-by-Humming", International Journal of Multimedia Information Retrieval, special issue on Hybrid Music Information Retrieval, In Press (accepted Nov. 2012).
[Springer][DOI][PDF][BibTex]
Interested in reading more? Please go to my Publications page.
Automatic Transcription
Extraction the (continuous) pitch of the melody is the first step towards transcription into notes (a.k.a. symbolic notation). Automatic transcription has a very wide range of uses, including composition, music education and music analysis. Importantly, automatic transcription can help us create symbolic representations of pieces that belong to music traditions which, unlike Western music, don't have an established score notation! One such example is Flamenco music, and you can read more about automatic transcription of Flamenco singing here:
E. Gómez, F. Cañadas, J. Salamon, J. Bonada, P. Vera and P. Cabañas, "Predominant Fundamental Frequency Estimation vs Singing Voice Separation for the Automatic Transcription of Accompanied Flamenco Singing", in Proc. 13th International Society for Music Information Retrieval Conference (ISMIR 2012), Porto, Portugal, October 2012.
[ISMIR][BibTeX]
Interested in reading more? Please go to my Publications page.
Genre Classification
Musical genres are distinguished by their different musical characteristics. The set of characteristics used to define a genre is very large (and may vary from genre to genre and from person to person!), and can include instrumentation, rhythm, timbre, harmony, production method, and... the characteristics of the melody! Clearly, pop melodies are quite different from flamenco melodies, which are very different from soloist parts in an Opera for example! Thus, if we can extract the melody, we can compute different features to characterize it, and based on these features try to determine the musical genre of the piece from which the melody came. This could (for example) help us to automatically sort our personal music collection based on genre! You can read more about genre classification using melody characteristics here:
J. Salamon, B. Rocha and E. Gómez, "Musical Genre Classification using Melody Features Extracted from Polyphonic Music Signals", in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, March 25-30, 2012.
[ICASSP][PDF][BibTeX]
Interested in reading more? Please go to my Publications page.
Motif and Pattern Analysis
Some musical styles are characterized by the use of melodic motifs which repeat in different forms through the musical piece. Some sub-genres can even be distinguished based on the type of motifs used in their melodies. Automatic melody extraction is a necessary first step for the computational analysis of melodic motifs. In the following paper you can find information about melodic motif analysis in Flamenco music, where our algorithm was used for the melody extraction step:
A. Pikrakis, F. Gómez, S. Oramas, J. M. D. Báñez, J. Mora, F. Escobar, E. Gómez and J. Salamon, "Tracking Melodic Patterns in Flamenco Singing by Analyzing Polyphonic Music Recordings", in Proc. 13th International Society for Music Information Retrieval Conference (ISMIR 2012), Porto, Portugal, October 2012.
[ISMIR][BibTeX]
Interested in reading more? Please go to my Publications page.
Fun
Once you have the melody's pitch sequence, you can synthesize it with whichever instrument (or voice) you fancy! Check out my blog post on how to replace your favourite singer with a robot using the Vocaloid singing voice synthesizer!
Software
MELODIA - Melody Extraction vamp plug-in

The "MELODIA - Melody Extraction" vamp plug-in is a software implementation of our melody extraction algorithm which is available online for free download for non-commercial use (i.e. for research and education).
MELODIA - Melody Extraction 1.0 is available for Windows, OSX and Linux and you can download it for free on the following site:
http://mtg.upf.edu/technologies/melodia
Here's a screenshot:
MELODIA - Melody Extraction 1.0 is available for Windows, OSX and Linux and you can download it for free on the following site:
http://mtg.upf.edu/technologies/melodia
Here's a screenshot:
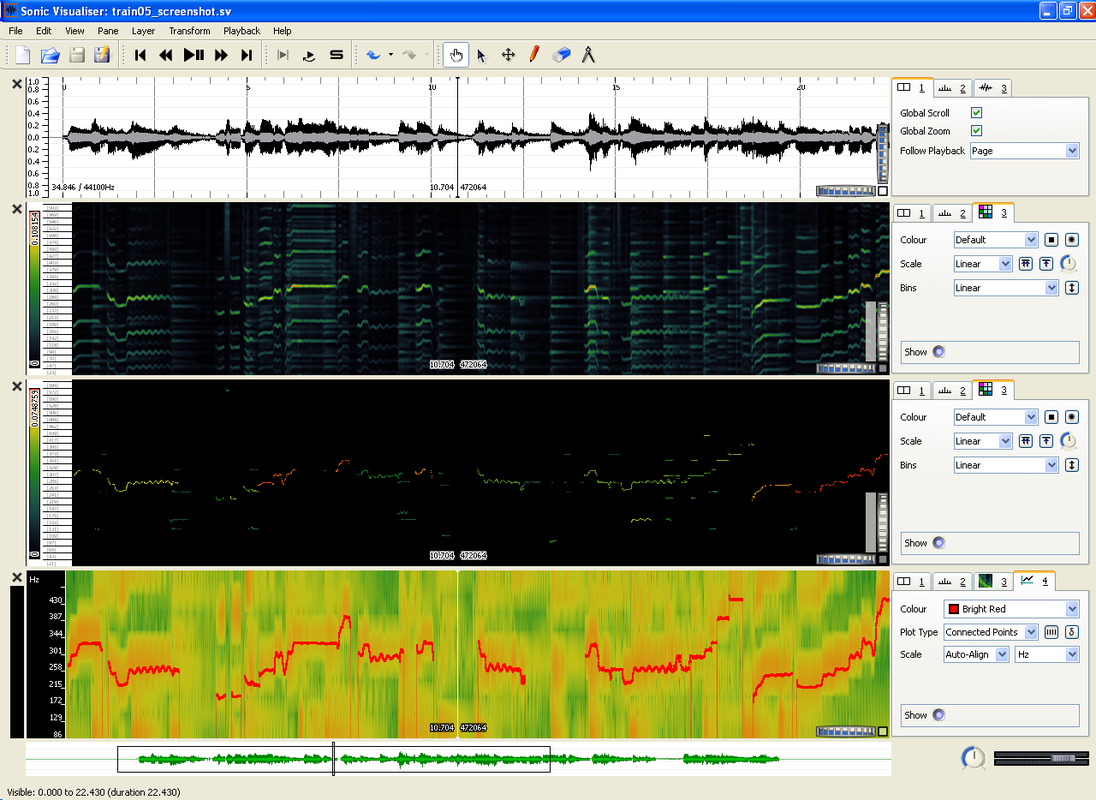
Above: MELODIA used in the Sonic Visualiser vamp host. Top pane: waveform. Second pane: salience function. Third pane: pitch contours (before contour filtering). Bottom pane: spectrogram with the final melody overlaid in red.
