Teaching machines to sense the world around them is a challenging problem. They need to:
- Learn to SEE the world
- Learn to HEAR the world
- Learn to LINK what they SEE with what they HEAR
We've seen dramatic progress in this area in recent years, but significant challenges remain:
- We have access to millions of videos, but they aren't labeled:
- Can we teach machines from videos without labels?
- In the same way objects move on screen, the sounds they make move too. Humans leverage this spatial correspondence between sight & sound to better understand the world:
- Can machines leverage this audiovisual spatial correspondence?
We present a novel self-supervised approach to spatial, audiovisual learning: we train a model to determine whether the left and right audio channels have been flipped, forcing it to reason about spatial localization across the visual and audio streams. We also show the technique generalizes to 360 videos with 3D sound by replacing left/right flipping with front/back audio rotation.
Here's the idea in a nutshell:
In a video with binaural audio, the location of what we see on screen corresponds to the perceived location of the sound. The spatial audio effect is thanks to the stereo audio with Left and Right channels:
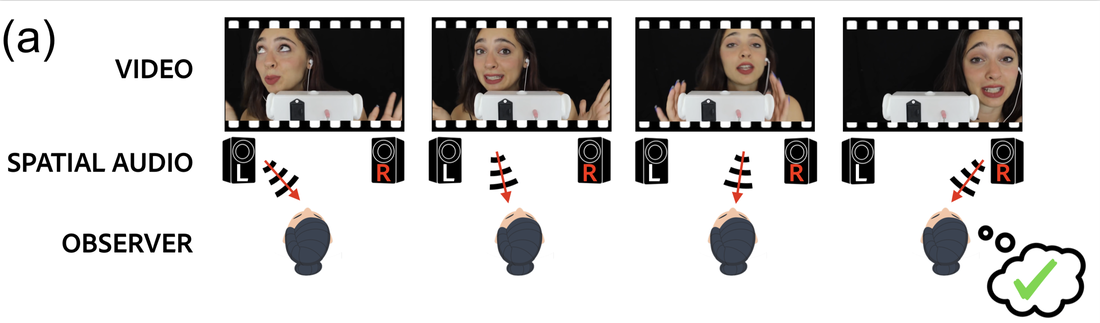
But what if we flip the left and right audio channels? Now the audiovisual spatial correspondence is broken, and the sound will be perceived as coming from the opposite direction:

We can leverage audiovisual spatial correspondence to learn a spatial audiovisual representation via self-supervision!
Concretely, we train a model to predict whether the audio channels have been flipped or not:
Concretely, we train a model to predict whether the audio channels have been flipped or not:
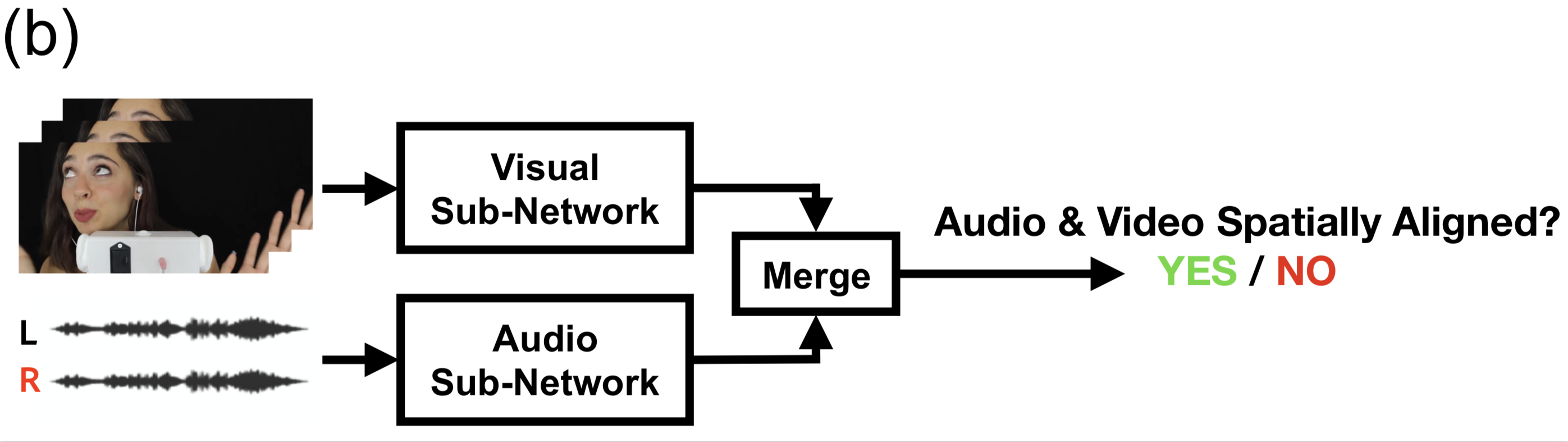
This surprisingly simple task results in a strong audiovisual representation that's useful in a variety of applications, including:
In case you missed in the demo video at the top of this page, here's the upmixing example again:
- Sounding face tracking
- On/off-screen sound source separation
- Automatic audio spatialization in 2D and 3D video, a.k.a upmixing: converting a video with mono audio to a video with stereo or ambisonic audio giving a surround sound effect where the sound of visible objects moves in synchrony with the object's motion.
In case you missed in the demo video at the top of this page, here's the upmixing example again:
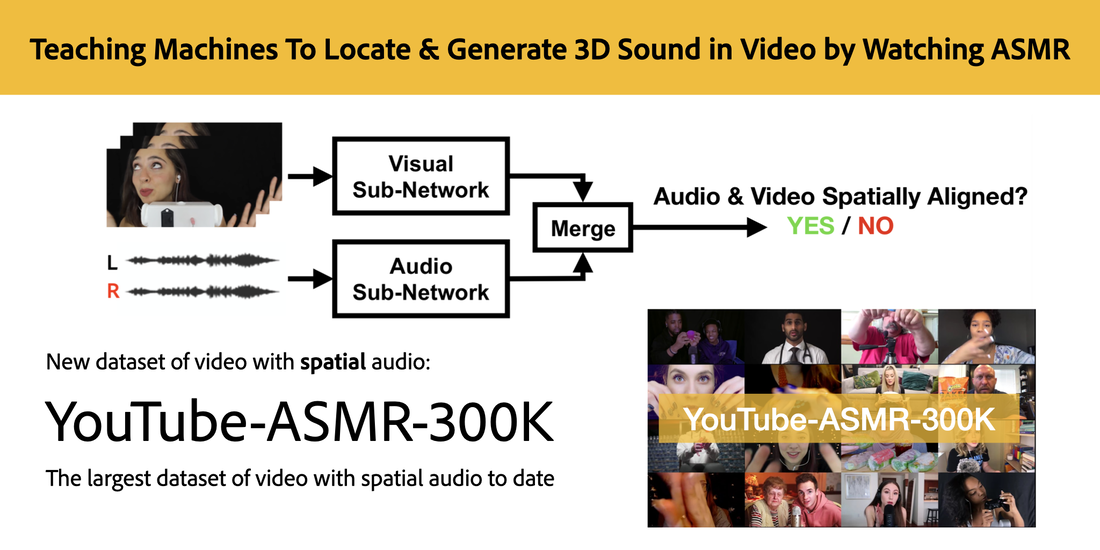
The YouTube-ASMR-300K dataset
To learn this spatial audiovisual representation, we compiled a new dataset containing hundreds of thousands of videos with spatial audio. But... where do you find video with spatial audio?
Cue in ASMR videos to the rescue!
ASMR (autonomous sensory meridian response) videos typically feature an individual actor or "ASMRtist" making different sounds while facing towards a camera set up with stereo/binaural or paired microphones. Some people watch ASMR videos to fall asleep. Others enjoy the tingling sensation the spatial audio gives them. Others can't stand them. However people react to ASMR, one thing is clear - ASMR videos are trending on YouTube... in fact, there are millions of them!
And here's the important part - the audio in these videos contains binaural cues such that there is strong audiovisual correspondence between the visual and spatial audio cues.
We're delighted to formally release the YouTube-ASMR-300K dataset, the largest video dataset with spatial audio to date:
Cue in ASMR videos to the rescue!
ASMR (autonomous sensory meridian response) videos typically feature an individual actor or "ASMRtist" making different sounds while facing towards a camera set up with stereo/binaural or paired microphones. Some people watch ASMR videos to fall asleep. Others enjoy the tingling sensation the spatial audio gives them. Others can't stand them. However people react to ASMR, one thing is clear - ASMR videos are trending on YouTube... in fact, there are millions of them!
And here's the important part - the audio in these videos contains binaural cues such that there is strong audiovisual correspondence between the visual and spatial audio cues.
We're delighted to formally release the YouTube-ASMR-300K dataset, the largest video dataset with spatial audio to date:

To download YouTube-ASMR-300K, please visit our companion website:
https://karreny.github.io/telling-left-from-right/
https://karreny.github.io/telling-left-from-right/
Learn more
You can also learn more about our work by reading our CVPR 2020 paper:
Telling Left From Right: Learning Spatial Correspondence of Sight and Sound
Karren Yang, Bryan Russell, Justin Salamon
The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 9932-9941.
[CVF][PDF][BibTeX]
Telling Left From Right: Learning Spatial Correspondence of Sight and Sound
Karren Yang, Bryan Russell, Justin Salamon
The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 9932-9941.
[CVF][PDF][BibTeX]
 RSS Feed
RSS Feed
