We're excited to announce the release of OpenL3, an open-source deep audio embedding based on the self-supervised L3-Net. OpenL3 is an improved version of L3-Net, and outperforms VGGish and SoundNet (and the original L3-Net) on several sound recognition tasks. Most importantly, OpenL3 is open source and readily available for everyone to use: if you have TensorFlow installed just run pip install openl3 and you're good to go!
Full details are provided in our paper:
Look, Listen and Learn More: Design Choices for Deep Audio Embeddings
J. Cramer, H.-H. Wu, J. Salamon, and J. P. Bello.
IEEE Int. Conf. on Acoustics, Speech and Signal Proc. (ICASSP), pp 3852-3856, Brighton, UK, May 2019.
[IEEE][PDF][BibTeX][Copyright]
Full details are provided in our paper:
Look, Listen and Learn More: Design Choices for Deep Audio Embeddings
J. Cramer, H.-H. Wu, J. Salamon, and J. P. Bello.
IEEE Int. Conf. on Acoustics, Speech and Signal Proc. (ICASSP), pp 3852-3856, Brighton, UK, May 2019.
[IEEE][PDF][BibTeX][Copyright]
How well does it work?
Here's a comparison of classification results on three environmental sound datasets using embeddings from OpenL3 (blue), SoundNet (orange) and VGGish (green) as input to a simple 2-layer MLP:
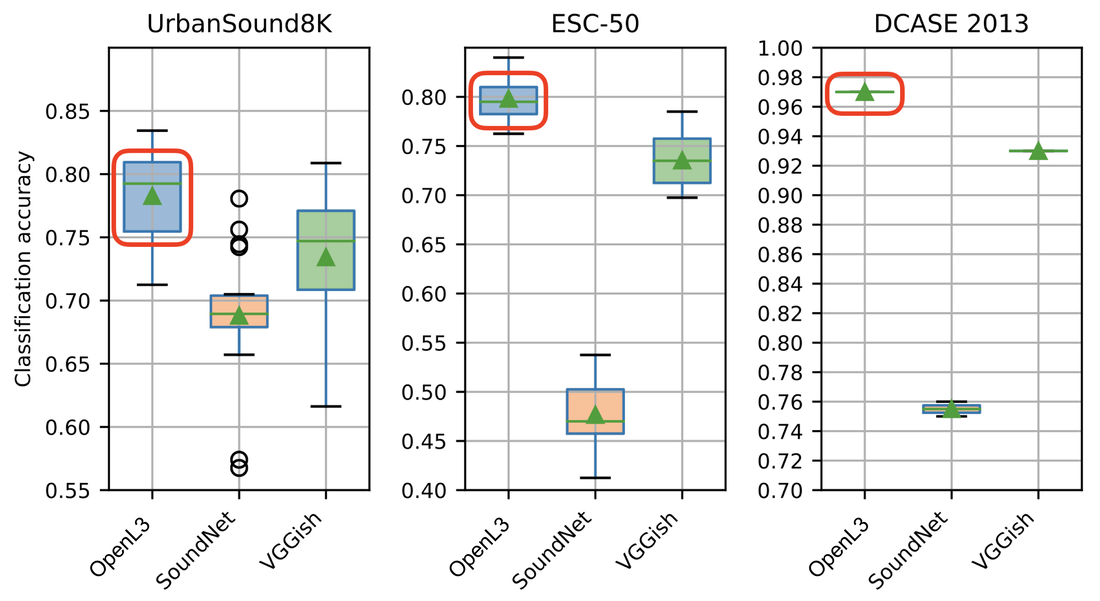
Using OpenL3 we are able to match the current state of the art on UrbanSound8K, the most challenging of the three datasets, using a simple MLP without any of the tricks usually necessary for relatively small datasets (such as data augmentation).
Using OpenL3
Installing OpenL3, a Python module, is as easy as calling (assuming TensorFlow is already installed):
$ pip install openl3
Once installed, using OpenL3 in python can be done like this (simplest use case without setting custom parameter values):
import openl3
import soundfile as sf
audio, sr = sf.read('/path/to/file.wav')
embedding, timestamps = openl3.get_embedding(audio, sr)
We also provide a command-line interface (CLI) that can be launched by calling "openl3" from the command line:
$ openl3 /path/to/file.wav
The API (both python and CLI) includes more options such as changing the hop size used to extract the embedding, the output dimensionality of the embedding and several other parameters. A good place to start is the OpenL3 tutorial.
How was OpenL3 trained?
OpenL3 is an improved version of L3-Net by Arandjelovic and Zisserman, which is trained on a subset of AudioSet using self-supervision by exploiting the correspondence between sound and visual objects in video data:
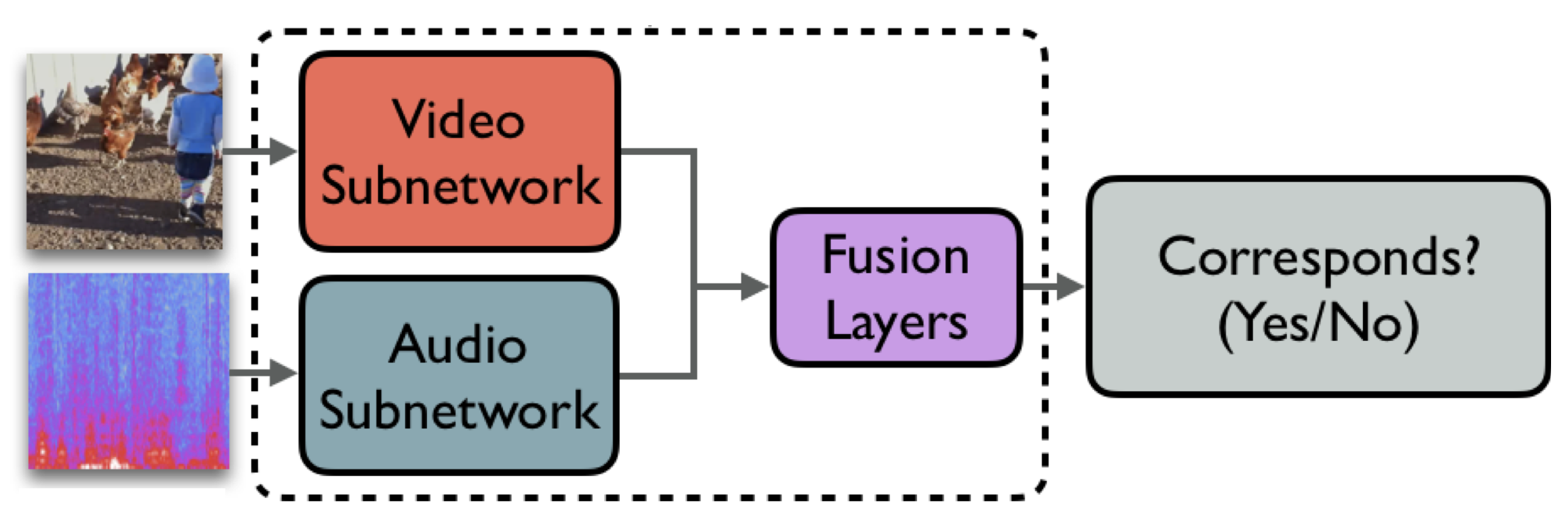
The embedding is obtained by taking the output of the final convolutional layer of the audio subnetwork. For more details please see our paper.
We look forward to seeing what the community does with OpenL3!
...and, if you're attending ICASSP 2019, be sure to stop by our poster on Friday, May 17 between 13:30-15:30 (session MLSP-P17: Deep Learning V, Poster Area G, paper 2149)!
We look forward to seeing what the community does with OpenL3!
...and, if you're attending ICASSP 2019, be sure to stop by our poster on Friday, May 17 between 13:30-15:30 (session MLSP-P17: Deep Learning V, Poster Area G, paper 2149)!
 RSS Feed
RSS Feed
