
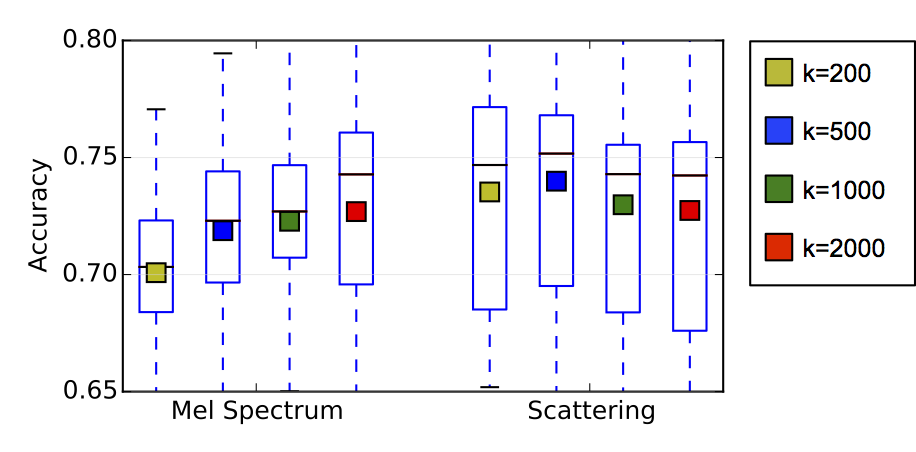
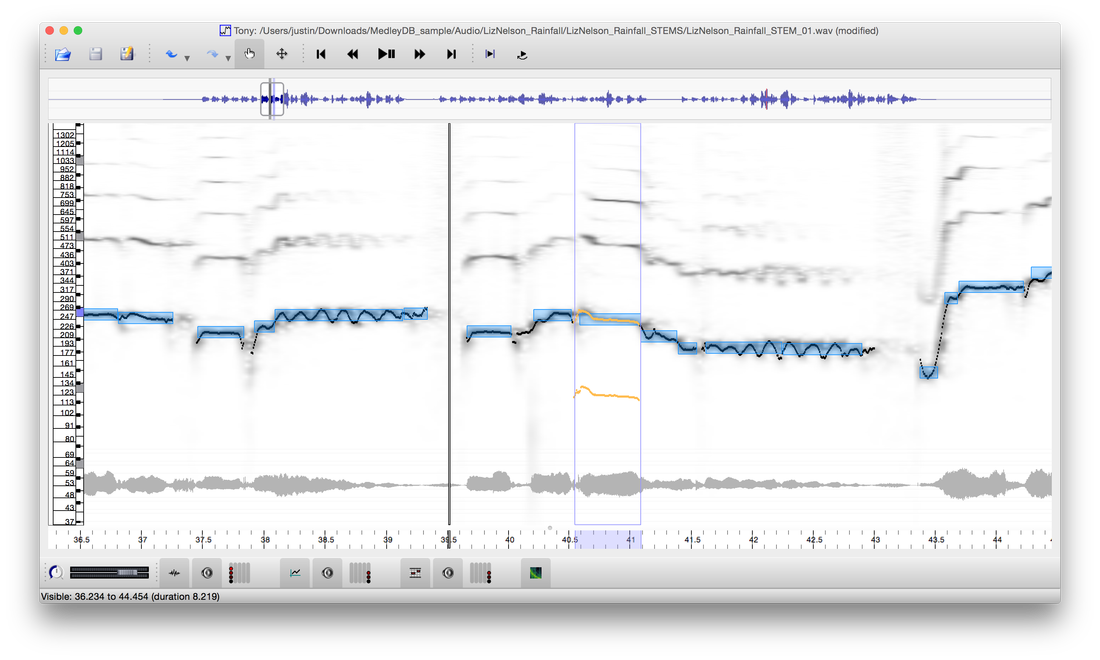
Due to the scarcity of labeled data, most melody extraction algorithms do not rely on fully data-driven processing blocks but rather on careful engineering. For example, the Melodia melody extraction algorithm employs a pitch contour selection stage that relies on a number of heuristics for selecting the melodic output. In this paper we explore the use of a discriminative model to perform purely data-driven melodic contour selection. Specifically, a discriminative binary classifier is trained to distinguish melodic from non-melodic contours. This classifier is then used to predict likelihoods for a track’s extracted contours, and these scores are decoded to generate a single melody output. The results are compared with the Melodia algorithm and with a generative model used in a previous study. We show that the discriminative model outperforms the generative model in terms of contour classification accuracy, and the melody output from our proposed system performs comparatively to Melodia. The results are complemented with error analysis and avenues for future improvements.
For further details please see our paper:
R. Bittner, J. Salamon, S. Essid and J. P. Bello. "Melody Extraction by Contour Classification". Proc. 16th International Society for Music Information Retrieval Conference (ISMIR 2015), Malaga, Spain, Oct. 2015.
[ISMIR][PDF][BibTex]
For further details please see our paper:
R. Bittner, J. Salamon, S. Essid and J. P. Bello. "Melody Extraction by Contour Classification". Proc. 16th International Society for Music Information Retrieval Conference (ISMIR 2015), Malaga, Spain, Oct. 2015.
[ISMIR][PDF][BibTex]




 RSS Feed
RSS Feed
